Nano-vLLM 代码解析
Study LLM infer infra from nano-vllm
Nano-vLLM 代码解析
项目概述
在大语言模型(LLM)推理领域,平衡性能、内存占用与部署复杂度一直是开发者面临的核心挑战。Nano-vLLM 是一个轻量级、高性能的 LLM 推理框架,为学习 vllm 框架打下基础。
作为一款聚焦推理优化的框架,Nano-vLLM 实现了多项业界公用的推理技术,核心特性包括:
- 高效 KV 缓存管理:采用基于 block 的缓存架构,支持智能复用与动态分配,最大化显存利用率
- 智能请求调度:分离 prefill/decode 阶段,优化批处理效率,平衡延迟与吞吐量
- 灵活张量并行:支持模型参数分布式部署,轻松扩展至大规模模型推理场景
- CUDA 图加速:减少 CPU-GPU 通信开销,显著提升小批量推理性能
接下来,我们将深入剖析 Nano-vLLM 的核心架构与实现细节,从引擎设计到调度机制,再到性能优化技术,全面了解这款轻量级推理框架的工作原理。
目录
LLMEngine 1.1 初始化 1.2 engine generate()
Scheduler 2.1 初始化 2.1.1 计算 num_kvcache_blocks 的过程 2.2 调度流程 2.2.1 调度上下文 call stack 2.2.2 调度核心 schedule
核心数据结构 3.1 Sequence 类 3.2 KVCache Block 管理 3.2.1 BlockManager 3.3 分配 Block (alloc) 3.4 释放 Block (dealloc)
ModelRunner 4.1 初始化 4.2 推理执行流程 4.2.1 输入准备 4.2.2 CUDA图加速 4.3 采样器 (Sampler)
张量并行 (Tensor Parallelism) 5.1 QKVParallelLinear (QKV_proj) 5.2 MergedColumnParallelLinear (MLP_gate_up) 5.3 RowParallelLinear (output_proj, MLP_down)
torch.distributed 6.1 初始化与配置 6.2 核心通信操作 6.3 进程间通信机制 6.4 性能优化与特点
首先,我们通过流程图看一下整个 Nano-vLLM 的工作流程以及各个模块之间的关系。有个宏观的印象。
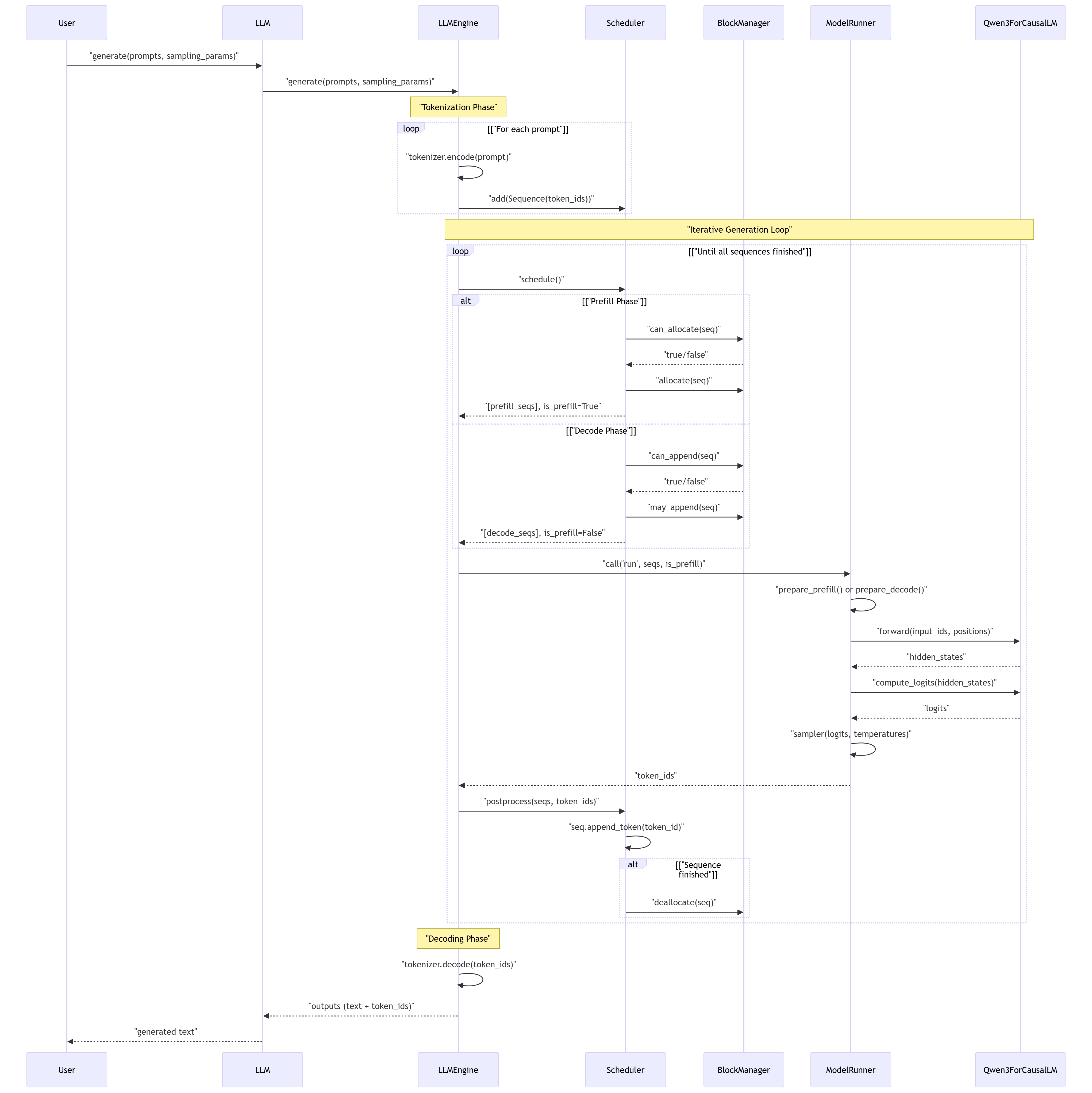
该流程图出自 deepwiki
1. LLMEngine
1.1 初始化
LLMEngine 初始化会初始化以下几个成员:
- config:从模型和 kwargs 中解析出的配置对象,包含模型路径、张量并行大小、KV 缓存大小等参数
- model_runner:模型执行引擎,负责在每个张量并行进程中执行模型推理
- tokenizer:用于将文本转换为模型输入 token 的分词器
- scheduler:请求调度器,负责管理和分配推理请求
初始化好这几个成员之后,由他们相互配合完成整个推理服务的流程。
根据 TP 数量,启动对应的进程,然后在每个进程中各自初始化 model_runner,tokenizer, schedule 这些。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class LLMEngine:
def __init__(self, model, **kwargs):
config_fields = {field.name for field in fields(Config)}
config_kwargs = {k: v for k, v in kwargs.items() if k in config_fields}
config = Config(model, **config_kwargs)
self.ps = []
self.events = []
## here create a process with spawn mode, to avoid CUDA fork issue
ctx = mp.get_context("spawn")
for i in range(1, config.tensor_parallel_size):
## create process for each TP with spawn mode (with new Python Interpreter)
event = ctx.Event()
process = ctx.Process(target=ModelRunner, args=(config, i, event))
process.start()
self.ps.append(process)
self.events.append(event)
self.model_runner = ModelRunner(config, 0, self.events)
self.tokenizer = AutoTokenizer.from_pretrained(config.model, use_fast=True)
config.eos = self.tokenizer.eos_token_id
self.scheduler = Scheduler(config)
atexit.register(self.exit)
这里看一下 spawn
1
ctx = mp.get_context("spawn")
补充说明:使用 spawn 作为进程启动方法是深度学习框架(如 PyTorch、vLLM、nano-vllm)处理 GPU 时的标准做法。原因是:
- 避免 GPU 上下文冲突:
spawn启动全新进程,不继承父进程的 GPU 状态,避免了硬件驱动不支持的内存复制问题,防止死锁或初始化错误 - 避免多线程死锁:
spawn不会继承父进程混乱的锁状态,解决了多线程环境下的死锁风险
相比默认的 fork 方法,spawn 虽然启动速度稍慢,但在 GPU 环境下提供了更稳定的运行保障
1.2 engine generate()
LLMEngine 的核心功能:
- 每次有 prompt 请求,调用 generate() 时,会将用户输入的 prompt 转换为 Sequence,然后通过 add_request() 方法添加到 Scheduler 进行排队,Scheduler 负责统一的请求调度。
- 内部有一个大的 while 循环,通过 is_finished() 监测是否所有请求都完成,如果有未完成的请求,每次调用 step() 进行一步生成操作。
- step() 内部总共三步:
- 通过 Scheduler.schedule() 获得当前应该执行的 seq,并确定是 prefill 还是 decode 阶段
- 由 model_runner 执行推理计算
- Scheduler.postprocess() 进行后处理,主要是将生成的 token 添加到序列中,并检查是否达到结束条件
- 统计 prefill/decode 的性能指标(吞吐量)并实时打印
- 所有请求执行结束后返回包含生成文本和 token_ids 的字典列表(不支持流式输出)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def generate(
self,
prompts: list[str] | list[list[int]],
sampling_params: SamplingParams | list[SamplingParams],
use_tqdm: bool = True,
) -> list[str]:
if use_tqdm:
pbar = tqdm(total=len(prompts), desc="Generating", dynamic_ncols=True)
if not isinstance(sampling_params, list):
sampling_params = [sampling_params] * len(prompts)
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp)
outputs = {}
prefill_throughput = decode_throughput = 0.
while not self.is_finished():
t = perf_counter()
output, num_tokens = self.step()
if use_tqdm:
if num_tokens > 0:
prefill_throughput = num_tokens / (perf_counter() - t)
else:
decode_throughput = -num_tokens / (perf_counter() - t)
pbar.set_postfix({
"Prefill": f"{int(prefill_throughput)}tok/s",
"Decode": f"{int(decode_throughput)}tok/s",
})
for seq_id, token_ids in output:
outputs[seq_id] = token_ids
if use_tqdm:
pbar.update(1)
outputs = [outputs[seq_id] for seq_id in sorted(outputs.keys())]
outputs = [{"text": self.tokenizer.decode(token_ids), "token_ids": token_ids} for token_ids in outputs]
if use_tqdm:
pbar.close()
return outputs
LLMEngine 作为框架的核心协调者,其高效运行离不开智能的请求调度机制。接下来我们将深入探讨 Nano-vLLM 中的 Scheduler 组件,了解它如何管理请求队列、分配计算资源以及优化推理效率。
2. Scheduler
2.1 初始化
1
2
3
4
5
6
7
8
9
class Scheduler:
def __init__(self, config: Config):
self.max_num_seqs = config.max_num_seqs
self.max_num_batched_tokens = config.max_num_batched_tokens
self.eos = config.eos
self.block_manager = BlockManager(config.num_kvcache_blocks, config.kvcache_block_size)
self.waiting: deque[Sequence] = deque()
self.running: deque[Sequence] = deque()
Schedule 初始化时用到的信息,除了 waiting_queue 和 running_queue 外均来自传入的 config。其中:
config.max_num_seqs,config.max_num_batched_tokens是用户输入内容config.eos从模型配置读入config.num_kvcache_blocks,config.kvcache_block_size是 LLMEngine 初始化过程中,在ModelRunner初始化时进行计算赋值的;计算方式是通过 dummy run 执行一遍,记录下峰值内存(peak memory),然后根据峰值内存、模型大小、kvcache_block_size以及可用显存大小来计算可分配的num_kvcache_blocks。
2.1.1 计算 num_kvcache_blocks 的过程
这里记录一下代码的主要部分,去掉了无关部分。
这里有一点需要注意,ModelRunner 初始化时,分配好所有的 kvcache blocks 后,直接将其赋值给 model 的 Attention layer,供后续 attention 计算使用。 为什么 Attention layer 的 kvcache 在这里赋值?因为 block 数量只有在 ModelRunner 这里才通过 warmup 计算得出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class ModelRunner:
def __init__(self, config: Config, rank: int, event: Event | list[Event]):
self.config = config
self.warmup_model() # 这里 dummy run 跑一遍,同时用
self.allocate_kv_cache() # torch.cuda.memory_stats 记录显存状态
def allocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0
self.kv_cache = torch.empty(2, hf_config.num_hidden_layers, config.num_kvcache_blocks, self.block_size, num_kv_heads, head_dim)
# 下面的代码将分配好的 kv_cache(所有的 kvcache_blocks)逐层赋值给 attention,供后续 attention 计算时使用
layer_id = 0
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1
KVCache_block 的管理方式可参考后续章节 KVCache Block 管理
Schedule 的初始化工作到这里基本结束了。
2.2 调度流程
2.2.1 调度上下文 call stack
schedule 的调度是按照 LLMEngine.generate() –> LLMEngine.step() –> schedule.schedule() 的方式进行调度。
- LLMEngine.generate() 内部有个 while 循环,退出条件是所有请求都调度完成
- LLMEngine.step() 调用 schedule.schedule() 得到当前应该进行的 seq,然后调用 model_runner 来执行这个 seq,接下来用 schedule.postprocess() 判断当前请求是否完成,如果完成则在 schedule 总进行资源释放,并将该 seq 状态设置为
SequenceStatus.FINISHED. - schedule.schedule() 判断当前 kvcache block 资源以及config 限制,按照先 prefill 再 decode 的顺序进行 seq 调度/抢占。
2.2.2 调度核心 schedule
schedule.schedule() 完整代码如下。可以看到调度策略是 prefill 优先:在不超过最大运行 seq 数量的前提下,如果 waiting queue 中有内容,则优先进行调度。直到 waiting queue 为空(表示无 prefill 请求在等待)才会调度 decode 请求。
- 调度 prefill 时,会检查 block_manager 是否可以分配新的 block,如果不行则等待;如果可以才会进行实际的调度
- 调度 decode 时,会判断 block_manager 是否可以添加新的 token,如果不行则会进行抢占,优先让 running 队列中的请求按照 FCLO(First Come Last Out) 的顺序进行释放(这里只需要释放一个 seq 即可,因为 decode 阶段每次只生成一个 token,只需要有一个 free block 即可);如果 running 队列为空,则释放当前 seq。这些被释放的 seq 会回到 waiting queue,在下一轮调度中被当作 prefill 请求优先调度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
def schedule(self) -> tuple[list[Sequence], bool]: # prefill scheduled_seqs = [] num_seqs = 0 num_batched_tokens = 0 while self.waiting and num_seqs < self.max_num_seqs: seq = self.waiting[0] if num_batched_tokens + len(seq) > self.max_num_batched_tokens or not self.block_manager.can_allocate(seq): break num_seqs += 1 self.block_manager.allocate(seq) num_batched_tokens += len(seq) - seq.num_cached_tokens seq.status = SequenceStatus.RUNNING self.waiting.popleft() self.running.append(seq) scheduled_seqs.append(seq) if scheduled_seqs: return scheduled_seqs, True # decode while self.running and num_seqs < self.max_num_seqs: seq = self.running.popleft() ## decode 阶段发先没有可用 block 了,则进行抢占 while not self.block_manager.can_append(seq): ## 如果有其他在 running 的 seq,则抢占其中一个 seq; ## pop() 淘汰最后进入 running 队列的请求; popleft() 淘汰最先进入的请求 if self.running: self.preempt(self.running.pop()) else: self.preempt(seq) break else: num_seqs += 1 self.block_manager.may_append(seq) scheduled_seqs.append(seq) assert scheduled_seqs self.running.extendleft(reversed(scheduled_seqs)) return scheduled_seqs, False
这里有个需要注意的点是 can_append() 函数,看到 Github 上面也有一些讨论 PR-65, PR-68。 刚开始笔者也很困惑判断这个函数的逻辑,在多轮 debug 后,有一些自己的理解,觉得这里的判断还是有些问题,应该改为: return len(self.free_block_ids) >= (len(seq) % self.block_size == 0)。
1
2
3
class BlockManager:
def can_append(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= (len(seq) % self.block_size == 1)
解释如下:
这个 can_append() 函数只在 decode 阶段被调用,所以只是 BlockManager 判断 decode 阶段是否可以往分配好的 block 中继续添加 token,而 decode 阶段每次只生成一个 token。这个时候再看这个函数:
- 如果添加的一个 token 可以放在该 seq 已经分配过的 block(last_block) 中,无需新的分配,此时 len(seq) % self.block_size == 0 为 False,len(self.free_block_ids) >= False 表示不管 free_block 是否还有,都返回 True。
- 如果添加的一个 token 不可以放在该 seq 已经分配过的 block 中,表示 seq 当前已有 token (prompt+generte) 刚好填满当前 seq 已经分配到的 blocks。此时 len(seq) % self.block_size == 0 为 True,len(self.free_block_ids) >= True 表示 free_block 至少要有一个 block,才会返回 True, 而这一个 Block 就是需要给新生成 token 进行分配的 block。
Scheduler 解析到此结束,整体推理服务高效运行离不开精心设计的数据结构支撑。无论是请求的表示、状态的跟踪,还是 KV 缓存块的管理,都依赖于 Nano-vLLM 中定义的核心数据结构。接下来,我们将详细分析这些数据结构的设计与实现。
3. 核心数据结构
3.1 Sequence 类
Sequence 类是 nano-vllm 中表示推理序列的核心数据结构,负责跟踪单个请求的所有状态信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Sequence:
block_size = 256 # 默认 block 大小
counter = count() # 序列 ID 生成器
def __init__(self, token_ids: list[int], sampling_params=SamplingParams()):
self.seq_id = next(Sequence.counter) # 唯一序列 ID
self.status = SequenceStatus.WAITING # 初始状态为等待
self.token_ids = copy(token_ids) # 存储所有 token IDs
self.last_token = token_ids[-1] # 最后一个 token
self.num_tokens = len(self.token_ids) # 当前序列长度
self.num_prompt_tokens = len(token_ids) # 提示词长度
self.num_cached_tokens = 0 # 已缓存的 token 数量
self.block_table = [] # 记录分配的 block ID
self.temperature = sampling_params.temperature # 采样温度
self.max_tokens = sampling_params.max_tokens # 最大生成 token 数
self.ignore_eos = sampling_params.ignore_eos # 是否忽略 EOS
# 各种属性和方法...
主要功能和属性:
- 序列状态管理:通过
status属性跟踪序列的状态(WAITING/RUNNING/FINISHED) - token 管理:存储所有 token_ids,并提供便捷的访问方法
- 缓存跟踪:记录已缓存的 token 数量和对应的 block 信息
- 采样参数:存储采样相关的参数
- 辅助属性:提供多种计算属性方便访问序列的不同部分(如
num_blocks,last_block_num_tokens等) - 序列化支持:实现了
__getstate__和__setstate__方法,支持序列的序列化和反序列化
3.2 KVCache Block 管理
3.2.1 BlockManager
nano-vllm 是由 Schedule 来初始化并管理 BlockManager 的。有了 num_kvcache_blocks 和 kvcache_block_size 后就可以进行 block 配置了。self.blocks 的处理也比较简单,计算出 blocks 的数量 num_blocks 后,初始化一个 num_blocks 长的 List 即可。核心管理组件有三个:
free_block_ids: deque 类型,管理空闲的 blockused_block_ids: set 类型,记录正在使用的 blockhash_to_block_id: dict 类型,记录 block 内 token_id 的 hash 值到 block 的映射
1
2
3
4
5
6
7
8
class BlockManager:
def __init__(self, num_blocks: int, block_size: int):
self.block_size = block_size
self.blocks: list[Block] = [Block(i) for i in range(num_blocks)]
self.hash_to_block_id: dict[int, int] = dict()
self.free_block_ids: deque[int] = deque(range(num_blocks))
self.used_block_ids: set[int] = set()
这里需要注意一下 Block 类,它是管理 kvcache_block 的最小单元,主要包含该 block 的 hash、ref_count、token_ids 和 block_id;还需注意,初始化后的 Block 的 self.token_ids 只是一个空列表,在后续执行任务时会实时使用 alloc/update 将真实的 token_ids 填入对应 Block 的列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Block:
def __init__(self, block_id):
self.block_id = block_id
self.ref_count = 0
self.hash = -1
self.token_ids = []
def update(self, hash: int, token_ids: list[int]):
self.hash = hash
self.token_ids = token_ids
def reset(self):
self.ref_count = 1
self.hash = -1
self.token_ids = []
3.3 分配 Block (alloc)
- Schedule 调度的 prefill 请求会调用
self.block_manager.can_allocate(seq)来判断当前 block 状态是否可以满足 seq 的需求,如果满足则会进行 block 分配。
1
2
def can_allocate(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= seq.num_blocks
- prefill 阶段的分配
prefill 阶段的分配逻辑由 BlockManager.allocate() 函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def allocate(self, seq: Sequence):
assert not seq.block_table # 确保是首次分配
h = -1
cache_miss = False
for i in range(seq.num_blocks):
token_ids = seq.block(i) # 获取当前 block 对应的 token_ids
# 如果 token_ids 可以放满一个 block 则计算 hash,否则 hash 值为 -1
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1
block_id = self.hash_to_block_id.get(h, -1)
# 检查缓存是否命中且 token_ids 匹配
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss:
# 缓存未命中,申请新的 block
block_id = self.free_block_ids[0]
block = self._allocate_block(block_id)
else:
# 缓存命中,更新统计信息
seq.num_cached_tokens += self.block_size
if block_id in self.used_block_ids:
# block 已被使用,增加引用计数
block = self.blocks[block_id]
block.ref_count += 1
else:
# block 未被使用,直接分配
block = self._allocate_block(block_id)
# 如果 block 填充满,则更新其 hash 和 token_ids
if h != -1:
block.update(h, token_ids)
self.hash_to_block_id[h] = block_id
# 将 block_id 添加到序列的 block_table 中
seq.block_table.append(block_id)
主要流程:
- 2.1 断言
seq.block_table为空,确保是首次分配 - 2.2 遍历需要分配的 block 数量
- 2.3 获取当前 block 对应的
token_ids - 2.4 如果
token_ids可以放满一个 block 则计算 hash 值,否则 hash 值为 -1(代表该 block 未填充满) - 2.5 根据 hash 值查找是否存在缓存命中,如果缓存未命中或 token_ids 不匹配,则标记为 cache_miss
- 2.6 如果 cache_miss,则从 free_block_ids 中申请新的 block
- 2.7 如果缓存命中,则根据 block 是否已被使用,决定是增加引用计数还是直接分配
- 2.8 如果 block 填充满(h != -1),则更新 block 的 hash 和 token_ids
- 2.9 将 block_id 添加到
seq.block_table中
- decode 阶段的分配
decode 阶段的分配逻辑由 BlockManager.may_append() 函数实现,该函数在每次生成新 token 后被调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def may_append(self, seq: Sequence):
block_table = seq.block_table
last_block = self.blocks[block_table[-1]] # 获取当前序列的最后一个 block
# 情况1:新 token 需要分配新 block(当前长度是 block_size 的倍数 +1)
if len(seq) % self.block_size == 1:
assert last_block.hash != -1 # 确保上一个 block 已填充满
block_id = self.free_block_ids[0] # 分配新的 block
self._allocate_block(block_id)
block_table.append(block_id) # 将新 block 添加到 block_table
# 情况2:新 token 刚好填满当前 block(当前长度是 block_size 的倍数)
elif len(seq) % self.block_size == 0:
assert last_block.hash == -1 # 确保当前 block 之前未填充满
token_ids = seq.block(seq.num_blocks-1) # 获取当前 block 的所有 token_ids
# 计算前缀 hash(如果有上一个 block)
prefix = self.blocks[block_table[-2]].hash if len(block_table) > 1 else -1
h = self.compute_hash(token_ids, prefix) # 计算当前 block 的 hash
last_block.update(h, token_ids) # 更新 block 的 hash 和 token_ids
self.hash_to_block_id[h] = last_block.block_id # 更新 hash 映射
# 情况3:新 token 放入当前 block 但未填满
else:
assert last_block.hash == -1 # 确保当前 block 未填充满
主要逻辑:
- 情况1:当
len(seq) % self.block_size == 1时,表示添加新 token 会开始一个新的 block- 此时需要分配一个新的 block 并添加到
block_table中
- 此时需要分配一个新的 block 并添加到
- 情况2:当
len(seq) % self.block_size == 0时,表示新 token 刚好填满当前 block- 此时需要计算当前 block 的 hash 值并更新
hash_to_block_id映射
- 此时需要计算当前 block 的 hash 值并更新
- 情况3:当
len(seq) % self.block_size为其他值时,表示新 token 放入当前 block 但未填满- 此时不需要额外操作
重要观察:只有当 block 被 tokens 填满时(情况2),才会将 token_ids 存入 block 并更新 hash 值,这样可以提高缓存命中率。
至此,Schedule 阶段 prefill/decode 的 block 分配都结束了,并且存放在 seqs 内,Schedule 会继续调用 model_runner 去实际执行这些 seqs。
3.4 释放 Block (dealloc)
释放 block 会发生在两个地方:
- 当没有 free block 给新 token 使用时,Schedule 会进行 FCLO(First Come Last Out) 抢占,被抢占的请求会进行 block 释放
- 在 postprocess() 内部释放已处理完成的 seq 的 blocks
释放 block 时会先判断 ref_count,如果有其他请求还在使用该 block,则只进行 ref--,不实际释放 block,从而实现 block 复用。
1
2
3
4
5
6
7
8
9
10
11
12
13
def deallocate(self, seq: Sequence):
for block_id in reversed(seq.block_table):
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0:
self._deallocate_block(block_id)
seq.num_cached_tokens = 0
seq.block_table.clear()
def _deallocate_block(self, block_id: int) -> Block:
assert self.blocks[block_id].ref_count == 0
self.used_block_ids.remove(block_id)
self.free_block_ids.append(block_id)
有了高效的数据结构和智能的调度机制,接下来需要一个强大的执行引擎来完成实际的模型推理。ModelRunner 作为 Nano-vLLM 的执行核心,负责加载模型、分配显存、执行计算以及采样生成结果。下面我们将深入分析 ModelRunner 的实现细节。
4. ModelRunner
4.1 初始化
当初始化时,如果 TP > 1,需要注意两点:
- 设置 ShareMemory,用于不同 TP 之间的小数据量通信,主要传递需要执行的 func 及参数
- rank0 节点初始化完成后继续执行,在
model_runner.call(func, **args)时将 func/args 写入 ShareMemory;后续 rank 阶段初始化完成后,则会进入 self.loop() 等待状态,持续读取 ShareMemory 直到获取内容,然后执行对应的函数,以此来保证不同 rank 之间推理阶段的同步。 以上 TP 间通信详情可以参考 6.3-进程间通信机制.
- rank0 节点初始化完成后继续执行,在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class ModelRunner:
def __init__(self, config: Config, rank: int, event: Event | list[Event]):
self.config = config
hf_config = config.hf_config
self.block_size = config.kvcache_block_size
self.enforce_eager = config.enforce_eager
self.world_size = config.tensor_parallel_size
self.rank = rank
self.event = event
## dist is a communication tools with meta operations(all_reduce, broadcast, send, recv..),
## here set the main process and block unitl all TP process to here.
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)
torch.cuda.set_device(rank)
default_dtype = torch.get_default_dtype()
torch.set_default_dtype(hf_config.torch_dtype)
torch.set_default_device("cuda")
self.model = Qwen3ForCausalLM(hf_config)
load_model(self.model, config.model)
self.sampler = Sampler()
self.warmup_model()
self.allocate_kv_cache()
if not self.enforce_eager:
self.capture_cudagraph()
torch.set_default_device("cpu")
torch.set_default_dtype(default_dtype)
if self.world_size > 1:
if rank == 0:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)
dist.barrier()
else:
dist.barrier()
self.shm = SharedMemory(name="nanovllm")
self.loop()
def call(self, method_name, *args):
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args)
method = getattr(self, method_name, None)
return method(*args)
model_runner 的入口函数是 def run(), 可以看到分为三步,prepare inputs, run_model, sampler。一个一个来看。
4.2 推理执行流程
ModelRunner 的核心是 run() 函数,它协调了整个推理过程:
1
2
3
4
5
6
7
8
9
10
11
12
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
# 准备输入数据
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
# 准备采样参数
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
# 执行模型推理
logits = self.run_model(input_ids, positions, is_prefill)
# 采样生成新 token
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
# 重置上下文
reset_context()
return token_ids
4.2.1 输入准备
prepare 分为 context 和 temperatures,temperatures 比较简单略过,这里记录一下 context 都需要准备哪些东西。
Prefill 阶段准备:
- 记录每条seq 包含的 input_ids,然后通过 input_ids 长度计算出来 positions, 以及 q/k 的lenght,这里最重要的是通过 seq_len 和 block size 计算 slot_mapping (举例说明)
- 计算好这些变量后,通过 set_context() 赋值给全局 context, 后续模型进行 attention forward 的时候会用 get_context() 拿到这些变量。
- 如果有命中的 KVCache,则还需要计算准备 block_table,其实只是将多个 seq 的 block_table 按照最长 seq 的 block_table 的长度进行对齐,估计是方便 attention kernel 进行计算。 如果没有命中 KVCache,则不需要这一步,KVCache 在 attention 计算之后会填入对应的 block_table。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
def prepare_prefill(self, seqs: list[Sequence]):
input_ids = []
positions = []
cu_seqlens_q = [0] # Q序列长度累积和
cu_seqlens_k = [0] # K序列长度累积和
max_seqlen_q = 0
max_seqlen_k = 0
slot_mapping = [] # KV缓存槽位映射
block_tables = None # 对齐后的block表
for seq in seqs:
seqlen = len(seq)
# 获取当前需要处理的token_ids(跳过已缓存的部分)
input_ids.extend(seq[seq.num_cached_tokens:])
# 生成位置信息
positions.extend(list(range(seq.num_cached_tokens, seqlen)))
# 计算Q和K的序列长度
seqlen_q = seqlen - seq.num_cached_tokens
seqlen_k = seqlen
# 更新累积和
cu_seqlens_q.append(cu_seqlens_q[-1] + seqlen_q)
cu_seqlens_k.append(cu_seqlens_k[-1] + seqlen_k)
# 更新最大序列长度
max_seqlen_q = max(seqlen_q, max_seqlen_q)
max_seqlen_k = max(seqlen_k, max_seqlen_k)
# 如果有block_table(不是warmup阶段),计算slot_mapping
if seq.block_table: # 如果是warmup阶段,block_table为空
for i in range(seq.num_cached_blocks, seq.num_blocks):
start = seq.block_table[i] * self.block_size
# 确定当前block的结束位置
if i != seq.num_blocks - 1:
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end)))
# 如果有前缀缓存(cu_seqlens_k > cu_seqlens_q),准备block_tables
if cu_seqlens_k[-1] > cu_seqlens_q[-1]:
block_tables = self.prepare_block_tables(seqs)
# 将数据转换为张量并移至GPU
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
# 设置全局上下文,供模型推理使用
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)
return input_ids, positions
Decode 阶段准备:
- decode 比 prefill 阶段需要准备的内容要少,只有 input_ids, positions, slot_mapping, 比 prefill 阶段多一个 context_lens。
- decode 阶段每一步都需要准备 block_table,其实就是update 对齐不同 seq 的 block_table 长度,估计是为了 attention kernel 计算方便。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = []
context_lens = [] # 每个序列的上下文长度
for seq in seqs:
# 只需要处理最后一个token
input_ids.append(seq.last_token)
# 最后一个token的位置
positions.append(len(seq) - 1)
# 当前序列的总长度
context_lens.append(len(seq))
# 计算当前token在KV缓存中的槽位
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)
# 将数据转换为张量并移至GPU
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
context_lens = torch.tensor(context_lens, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
# 准备对齐后的block_tables
block_tables = self.prepare_block_tables(seqs)
# 设置全局上下文,供模型推理使用
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)
return input_ids, positions
4.2.2 CUDA图加速
ModelRunner 支持 CUDA 图捕获来加速推理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@torch.inference_mode()
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
# Prefill阶段或强制eager模式或批量大小超过512时,使用eager模式
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))
else:
# 使用CUDA图加速
bs = input_ids.size(0)
context = get_context()
# 选择合适的CUDA图(根据批量大小)
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)]
graph_vars = self.graph_vars
# 更新图中的变量
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"].fill_(-1)
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"].zero_()
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
# 重放CUDA图
graph.replay()
return self.model.compute_logits(graph_vars["outputs"][:bs])
CUDA 图通过预先记录计算操作并重复执行来减少 CPU-GPU 通信开销,显著提高小批量推理的性能。
4.3 采样器 (Sampler)
nano-vllm 只实现了加了 temperatures 的 greedy-search 采样,比较简单:
1
2
3
4
5
def forward(self, logits: torch.Tensor, temperatures: torch.Tensor):
logits = logits.float().div_(temperatures.unsqueeze(dim=1))
probs = torch.softmax(logits, dim=-1)
sample_tokens = probs.div_(torch.empty_like(probs).exponential_(1).clamp_min_(1e-10)).argmax(dim=-1)
return sample_tokens
为了支持大规模模型的高效推理,Nano-vLLM 实现了张量并行技术,允许将模型参数分布在多个 GPU 上进行并行计算。这不仅突破了单卡显存限制,还能充分利用多卡计算资源提升推理性能。下面我们将深入探讨 Nano-vLLM 中张量并行的实现原理与技术细节。
5. 张量并行 (Tensor Parallelism)
这节主要讲一下 TP 情况下,model 是怎么 load 的,针对 $TP=1$ 和 $TP=2$ 场景下,以 Qwen3-4B-Thinking-2507 model load 为例。
Qwen3-4B-Thinking-2507 模型权重 shape 汇总:
| 模块 | 矩阵名称 | 输入维度 (In) | 输出维度 (Out) | 最终形状 (Shape) |
|---|---|---|---|---|
| Attention | q_proj | 2560 | 4096 ($32 \times 128$) | [2560, 4096] |
| k_proj | 2560 | 1024 ($8 \times 128$) | [2560, 1024] | |
| v_proj | 2560 | 1024 ($8 \times 128$) | [2560, 1024] | |
| o_proj | 4096 | 2560 | [4096, 2560] | |
| MLP (SwiGLU) | gate_proj (w1) | 2560 | 9728 | [2560, 9728] |
| up_proj (w3) | 2560 | 9728 | [2560, 9728] | |
| down_proj (w2) | 9728 | 2560 | [9728, 2560] | |
| Other | embed_tokens | 151936 | 2560 | [151936, 2560] |
| lm_head | 2560 | 151936 | [2560, 151936] |
补充说明:
- GQA (Grouped Query Attention): 可以看到
q_proj的输出维度是k/v_proj的 4 倍(32 heads vs 8 heads),这是典型的 GQA 设计,旨在减少显存占用并提升推理速度。 - SwiGLU 结构: MLP 层包含
gate和up两个并行的升维投影,随后通过down投影降维回 $d_{model}$。
5.1. QKVParallelLinear (QKV_proj)
继承自 ColumnParallelLinear, 在 Qwen3 中,QKV 通常会被打包成一个大的矩阵。由于采用 GQA(Grouped Query Attention),Q 与 KV 的头数不一致,切分时必须保证 完整的 Head 被分配到不同的卡上。
- 计算公式: $Total_Out = (n_{heads} + 2 \times n_{kv_heads}) \times d_{head}$
- TP=1 总输出维度: $(32 + 2 \times 8) \times 128 = 48 \times 128 = 6144$
| 维度参数 | TP=1 (单卡) | TP=2 (每张卡) | 切分说明 |
|---|---|---|---|
| Weight Shape | [2560, 6144] | [2560, 3072] | 列切分 (Column Split) |
| Q heads/卡 | 32 | 16 | $32 \div 2$ |
| KV heads/卡 | 8 | 4 | $8 \div 2$ |
5.2. MergedColumnParallelLinear (MLP_gate_up)
继承自 ColumnParallelLinear, SwiGLU 激活函数需要 gate_proj ($W1$) 和 up_proj ($W3$)。在 nano-vllm 中,为了减少算子调用次数,通常将这两个矩阵在 输出维度(列) 上合并。
- 计算公式: $Total_Out = 2 \times intermediate_size$
- TP=1 总输出维度: $2 \times 9728 = 19456$
| 维度参数 | TP=1 (单卡) | TP=2 (每张卡) | 切分说明 |
|---|---|---|---|
| Weight Shape | [2560, 19456] | [2560, 9728] | 列切分 (Column Split) |
注意: 在 $TP=2$ 时,每张卡实际上处理的是原模型中
gate_proj的前一半和up_proj的前一半(通过特定的存储排列实现)。
5.3. RowParallelLinear (output_proj, MLP_down)
继承自 LinearBase, 这类层作为 Attention 或 MLP 结构的最后一层,负责将切分后的特征“收拢”回 $d_{model}$ 维度。它们在 输入维度(行) 上进行切分。
| 矩阵名称 | TP=1 (单卡) | TP=2 (每张卡) | 切分说明 |
|---|---|---|---|
| output_proj (o) | [4096, 2560] | [2048, 2560] | 行切分 (Row Split) |
| MLP_down (w2) | [9728, 2560] | [4864, 2560] | 行切分 (Row Split) |
总结:nano-vllm 中的数据流向
在 $TP=2$ 的环境下,每一层内部的逻辑如下:
- 输入 $X$ 存在于两张卡上(完全相同)。
- ColumnParallel: 每张卡计算出自己那部分输出(QKV 或 Gate/Up),此时两张卡的数据是不一样的。
- RowParallel:
- 它接收上一层产生的局部输出。
- 在计算完矩阵乘法后,进行一次
All-Reduce算子操作。 All-Reduce之后,两张卡又重新获得了完整的、相同的激活值,准备进入下一层。
6 torch distributed
Nano-vLLM 基于 PyTorch 的 torch.distributed 模块实现了高效的张量并行通信,该模块提供了丰富的分布式通信原语,是实现跨 GPU 并行计算的核心基础设施。以下内容基于对源码的分析,引用的代码均来自实际实现。
6.1 初始化与配置
在 ModelRunner 初始化阶段,Nano-vLLM 会配置并初始化分布式环境。核心代码如下:
1
2
3
# 初始化分布式进程组
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)
torch.cuda.set_device(rank) # 将进程绑定到对应rank的GPU设备
关键配置:
- Backend (后端): 使用
nccl作为通信后端,这是 NVIDIA GPU 间通信的最优选择,提供了高性能的集合通信操作 - Address (地址): 使用固定的 TCP 地址
tcp://localhost:2333作为进程组的通信入口点 - World Size (全局大小): 等于张量并行度
tensor_parallel_size,即参与并行计算的 GPU 数量 - Rank (进程秩): 每个 GPU 进程的唯一标识符,范围从 0 到
world_size-1
6.2 核心通信操作
Nano-vLLM 主要使用以下通信操作实现张量并行:
- All-Reduce:
- 用于
RowParallelLinear层(如output_proj和MLP_down) - 核心实现代码:
1 2 3 4 5
def forward(self, x: torch.Tensor) -> torch.Tensor: y = F.linear(x, self.weight, self.bias if self.tp_rank == 0 else None) if self.tp_size > 1: dist.all_reduce(y) # 关键通信操作:聚合所有GPU的结果 return y
- 将所有 GPU 上的局部结果进行聚合(求和),并将完整结果广播回所有 GPU
- 是实现张量并行的核心通信原语
- 用于
- Barrier:
- 用于同步所有进程的执行进度
- 确保所有进程都完成某一阶段后才继续执行下一阶段
- 使用示例:
1 2 3 4 5 6
if rank == 0: self.shm = SharedMemory(name="nanovllm", create=True, size=2**20) dist.barrier() # 等待所有进程到达此点 else: dist.barrier() # 等待所有进程到达此点 self.shm = SharedMemory(name="nanovllm")
- 进程组管理:
- 初始化时创建进程组,退出时销毁
- 退出代码:
1 2 3 4
def exit(self): # 其他清理操作... torch.cuda.synchronize() dist.destroy_process_group() # 销毁进程组
6.3 进程间通信机制
Nano-vLLM 实现了一套基于共享内存的轻量级进程间通信机制,用于协调不同 rank 之间的执行。核心实现如下:
- 共享内存初始化:
1 2 3 4 5 6 7 8
if self.world_size > 1: if rank == 0: self.shm = SharedMemory(name="nanovllm", create=True, size=2**20) dist.barrier() else: dist.barrier() self.shm = SharedMemory(name="nanovllm") self.loop() # 非rank0进程进入等待循环
- 命令读取与执行:
1 2 3 4 5 6
def loop(self): while True: method_name, args = self.read_shm() # 从共享内存读取命令 self.call(method_name, *args) # 执行命令 if method_name == "exit": break
共享内存读写实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
def read_shm(self): self.event.wait() n = int.from_bytes(self.shm.buf[0:4], "little") # 读取数据长度 method_name, *args = pickle.loads(self.shm.buf[4:n+4]) # 读取命令和参数 self.event.clear() return method_name, args def write_shm(self, method_name, *args): data = pickle.dumps([method_name, *args]) # 序列化命令和参数 n = len(data) self.shm.buf[0:4] = n.to_bytes(4, "little") # 写入数据长度 self.shm.buf[4:n+4] = data # 写入命令和参数 for event in self.event: event.set() # 通知其他进程
工作原理:
- Rank 0 作为协调者: 负责接收外部请求并将任务分发给其他 rank
- 非 Rank 0 进程: 进入循环等待状态,通过共享内存接收命令并执行
- 事件同步: 使用
Event对象实现进程间的同步信号 - 命令传递: 使用
pickle序列化函数名和参数,通过共享内存传递
6.4 性能优化与特点
Nano-vLLM 在分布式通信方面具有以下特点和优化:
- 极简设计: 仅使用最必要的通信操作(All-Reduce、Barrier),避免复杂通信拓扑
- 共享内存优化: 使用
multiprocessing.shared_memory实现进程间快速通信,避免网络开销 - 按需通信: 仅在张量并行的必要阶段(如 RowParallelLinear 输出)进行 All-Reduce 通信
- NCCL 硬件加速: 充分利用 NCCL 后端的硬件加速特性
- 进程隔离: 通过
spawn方式启动进程,避免 GPU 上下文冲突
通过上述机制,Nano-vLLM 能够在多 GPU 环境下实现高效、稳定的张量并行推理,充分利用硬件资源提升模型性能。