KV Select
Introduction to a simple way of selecting core KV caches to improve decode throughput
简介
随着大型语言模型(LLM)在各行各业的广泛应用,其处理长文本的能力成为衡量模型性能的关键指标。然而,传统的Transformer架构在处理长序列时面临着一个根本性的挑战:计算量和内存占用随上下文长度呈线性甚至超线性的增长。KV Cache本身所带来的巨大内存开销和随之而来的读写延迟,成为了制约LLM推理效率,尤其是在处理超长上下文时的最关键瓶颈之一。
学术界和工业界提出了多种针对KV Cache的优化策略,这些策略通常可以被归纳为三个层次:令牌级、模型级和系统级优化:令牌级优化聚焦于对缓存中的单个token进行精细管理,包括选择、预算分配、合并、量化和低秩分解等多种手段;系统级优化则着眼于更宏观的层面,通过改进内存管理(如PagedAttention)、调度策略和利用特定硬件特性(如FlashAttention)来提升整体效率;模型级优化则聚焦于模型如何使用这些 KV Cache,最具有代表性的便是各种 KV Cache 稀疏化的算法。
KV Select
KV Select 是一类重要的 KV Cache 稀疏化的算法,其旨在选择对于 Attention 最重要的 KV token 参与 Attention 的计算以减少需要加载到显存以及参与计算的 token 数量。这类方法通常依赖于一些预设的静态规则或启发式算法来决定保留哪些KV对。例如,静态的“局部窗口”注意力机制又或者是 “Top-k” 等动态的启发式方法。
HATA
HATA(Hash-Aware Top-k Attention)是一种创新的、可训练的稀疏注意力算法,它巧妙地运用了一种名为“学习哈希”的技术,改变了我们在大规模向量集合中寻找最高相似度元素的方式 。其核心思想可以形象地理解为:与其费力地逐一比较每一个候选对象,不如给每个对象一个独特的“指纹”,然后通过比较这些指纹的快慢来快速筛选出最匹配的几个。这种方法将原本昂贵的精确计算过程,转变为一种高效的近似排序过程。
在执行Top-k注意力时,我们的最终目标仅仅是找出k个得分最高的注意力对。然而,传统的Top-k方法需要精确计算查询向量与所有键向量之间的点积得分,然后进行一次完整的排序操作来选出前k名。这个过程,特别是计算所有点积的步骤,计算成本极高。事实上,我们并不需要知道每一对Q-K组合的确切得分,只需要知道它们之间的相对顺序就足够了——只要能确认哪一对得分更高,就能保证选出正确的k个结果。
HATA: Trainable and Hardware-Efficient Hash-Aware Top-k Attention for Scalable Large Model Inference
KV Select 核心算法
HATA 进行 KV Select 的流程可以简单地概括为三步:1)计算哈希;2)计算Q-K 哈希值的汉明距离;3)排序并选择 Top-K
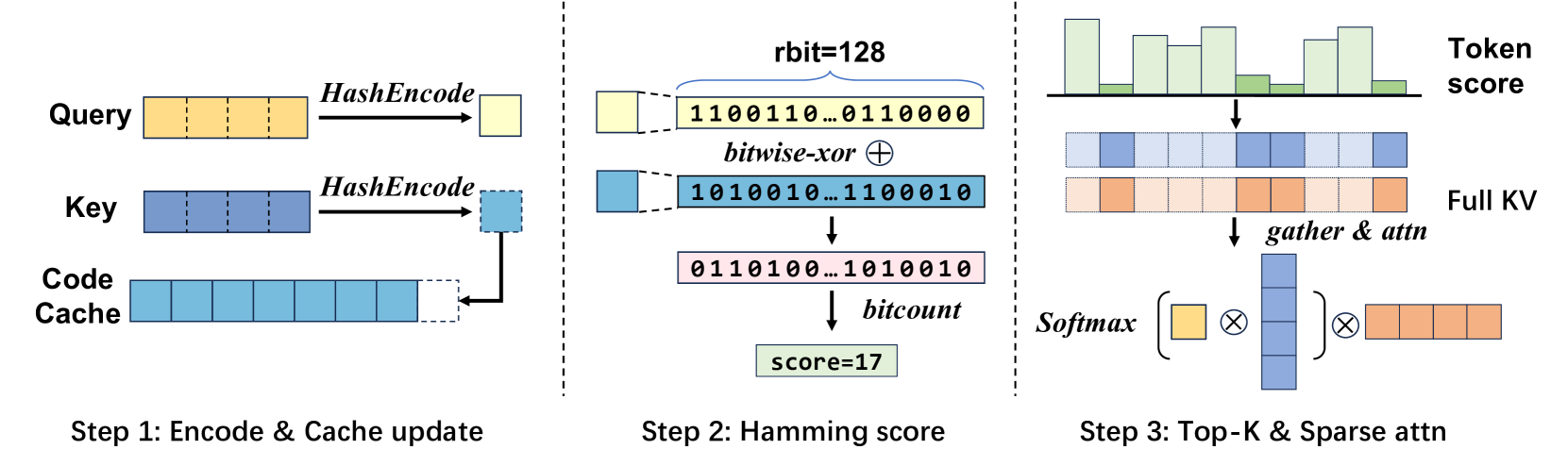
图片来源:HATA 论文,展示了 HATA 中 KV Select 的核心流程。
HATA 的核心组件——哈希函数——是完全可训练的。与那些使用固定哈希函数或启发式规则的方法不同,HATA的哈希函数是作为模型权重的一个补充,类似于 LoRA 微调的权重,可以在海量数据上通过反向传播和梯度下降进行端到端优化的。这意味着模型能够根据具体的下游任务(如问答、对话、代码生成)和数据分布,自动学习到一套最适合该场景的哈希策略。这种数据驱动的学习能力确保了稀疏化过程不仅高效,而且信息保真度高,能够在加速的同时维持甚至提升模型的准确率,避免了因盲目剪枝导致的性能损失。
Q-K token 与哈希权重进行矩阵乘转换到哈希空间后,会对哈希值进行比特压缩。一方面是为了后续计算汉明距离做准备,另一方面则是优化显存的使用。与 Transformer 引入 KV Cache 一样,在推理的过程中需要使用哈希值来计算汉明距离,但是我们可以通过缓存 token 的哈希向量的方式避免每一次都重新进行计算。通常额外缓存的 Hash Cache 仅占 KV Cache 总量的 $1/32$,这是一个可以接受的代价,甚至在结合 KV Cache 卸载的技术,比如 LMCache,我们可以完全忽略这一部分的 Cache 增量。
HATA 计算 Q-K 哈希向量的汉明距离来近似地计算 Q-K 向量的点积。前文中提到,HATA 会对哈希值值进行比特压缩,本质上是对哈希向量的每一个通道进行了一次二分类。根据局部敏感哈希(LSH)的一些基本原理,哈希向量的每一个通道对应于在 Q-K token 向量在一个超平面上的投影,压缩的过程就是对投影值进行取符号的过程。这些超平面的法向量的集合最终成为了哈希权重。在进行压缩了以后,Q-K 哈希向量就可以看作一个二进制表示的整数,计算其汉明距离将会比计算向量的点积的大量浮点运算来的快很多。
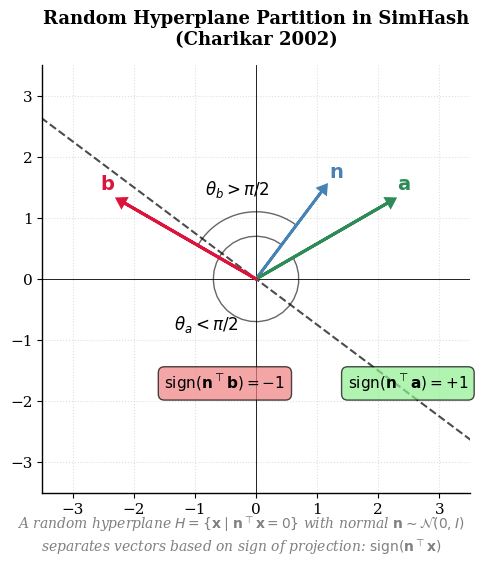
局部敏感哈希(LSH),首次由 Moses S. Charikar 在其论文 “Similarity Estimation Techniques from Rounding Algorithms” 中> 引入半正定规划(SDP)舍入算法的几何思想转换而成,建立了汉明距离与余弦相似度之间的精确概率对应关系。
SimHash 的本质是通过 $k$ 个随机超平面将高维空间划分为 $2^k$ 个区域,每个区域对应一个 $k$ 位二进制码。
随机超平面二分原理 \(\mathbb{E}\big[\operatorname{Hamming}(h(\mathbf{u}), h(\mathbf{v}))\big] = k \cdot \frac{\theta}{\pi} = k \cdot \frac{\arccos(\cos\theta)}{\pi}\) 该关系建立了汉明距离 ↔ 夹角 ↔ 余弦相似度 的确定性桥梁。
该算法已成为工业界近似最近邻搜索的基石技术之一,尤其在文本去重、推荐系统等场景中广泛应用。
简化实现
正如上文中的介绍,HATA 进行 KV Select 的算法的数学原理并不依赖于特定的哈希权重,也就是超平面法向量的集合,哈希权重训练的过程无非是寻找一组最合适的超平面。因此,在实际应用的时候,也可以采用完全随机的哈希权重,也能实现类似的效果,这将直接省去权重训练的成本。在实际的生产过程中,我们发现采用完全随机的哈希权重,在短上下文(<8k)的问答场景下,HATA 也有较好的精度表现。
另外,也可以对 K Cache 的 token 进行“打包”计算,将多个相邻的 K token 打包成 chunk 后与 Q 的哈希向量计算汉明距离,使用最小的汉明距离作为整个 chunk 与 Q 的汉明距离,作为 top-K 的依据,这样做法可以进一步提高显存和访问效率并减少 top-K 的计算量。
展望
相较于早期各类 KV Select 算法,比如 H2O 等,近期提出的各种 KV Select 算法不在只聚焦于如何人为地选择 KV Cache,其渐渐地将目光投向了如何让模型自己学会如何去选择重要的内容。较早的 InfiGem 算法以及本文中提到的 HATA,都会“后天”地训练模型来识别重要地内容;而 DeepSeek 的 NSA 则更加彻底,在模型的训练阶段,就将 KV Cache 的压缩以及筛选的能力内化到模型自身的能力中,这也令 DeepSeek 实现了卓越的长上下文的模型推理能力。如果将两者进行对比,就好像两个老板做决策,其中一个聘请了秘书先帮忙做一波提炼,好处是“即插即用”,只需要简单培训就可以工作,成本低,但相对的让秘书总结难免会损失一些以老板的经验来看重要的点;另一个则是老板根据自身的经验直接筛选重要的信息,效率更高,但老板为了积累这些经验需要付出地更多。
笔者认为,这是一个趋势:KV Cache 稀疏化的终极目标,不应只是“减少内存占用”,而是重新定义 Transformer 如何感知和处理长序列信息,是从“压缩显存”到“重塑注意力”。