Dual Chunk Attention
Introduction to Dual Chunk Attention

简介
dense Attention受制于显存开销和空间复杂度,导致大模型训练的上下文窗口无法一直扩展下去,这一限制也催生出了很多长度外推算法,训练阶段保持短上下文窗口,然后在推理阶段通过外推来扩展模型的上下文窗口,比较典型的就是Yarn 和 DCA。
翻看qwen的技术报告,多次提及了DCA这个算法,说明该算法效果不错且适合落地。
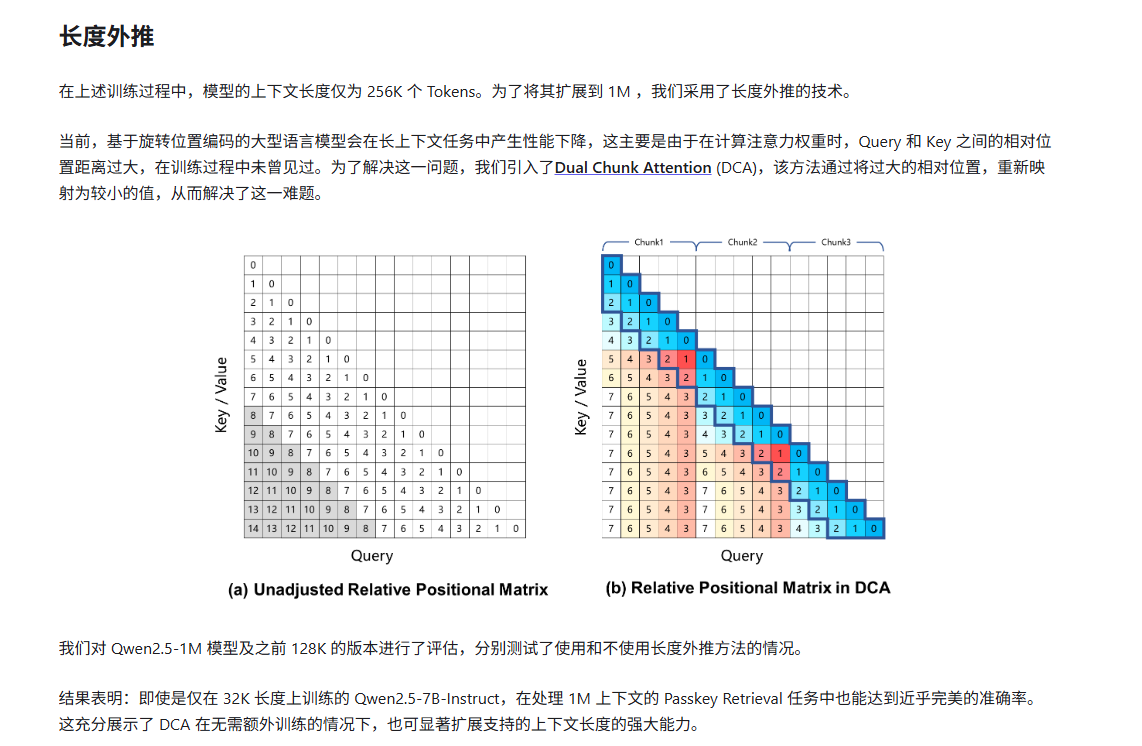
信息来源:Qwen2.5-1M Technical Report

文字来源:Qwen3-235B-A22B-Thinking-2507 huggingFace
Dual Chunk Attention (DCA) 是一种无需训练 (Training-Free) 的方法,旨在将大型语言模型 (LLM) 的上下文窗口扩展到支持超过 100k tokens,而无需进行持续训练 (Continual Training)。
这种方法具有重要的实际意义,因为它通过算法创新解决了 LLM 在处理超过预训练长度的文本时生成的连贯性问题,同时避免了微调 (Fine-tuning) 大规模模型所需的昂贵计算开销。
核心机制
原始的attention机制只有一套位置编码,随着输入序列的变大,Q K的相对位置也越来越大,直接外推位置编码往往会导致模型性能急剧下降,因为相对位置索引超出了模型在预训练阶段见过的分布范围。
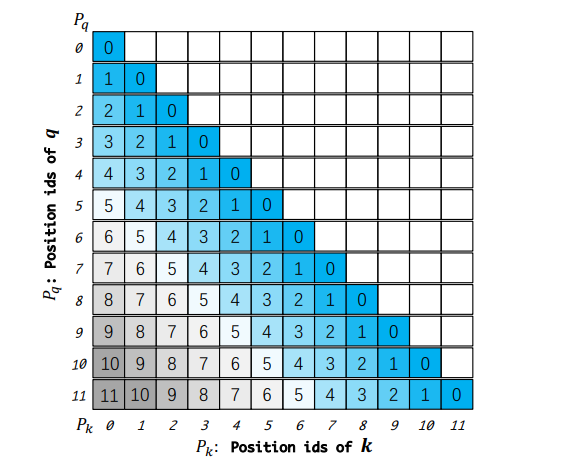
图 片来源:Dual Chunk Attention 论文,用数字来代表相对位置或位置编码。
DCA 通过切分的机制,将长序列的注意力计算分解,使得模型能够复用其熟悉的相对位置模式。DCA按chunk粒度将原始Attention分割成了三种,假设训练长度是8,chunk长度是4。
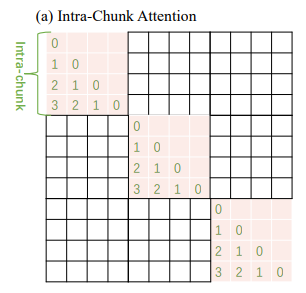
1. Chunk 内注意力(Intra-Chunk Attention)
关注同一个 Chunk 内部 token 之间的关系。由于 Chunk 的长度通常设定为模型预训练时的窗口大小(或更小),计算 Chunk 内部注意力时,相对位置索引完全落在模型预训练的分布范围内。这保证了模型对局部上下文的理解能力与预训练时保持一致。
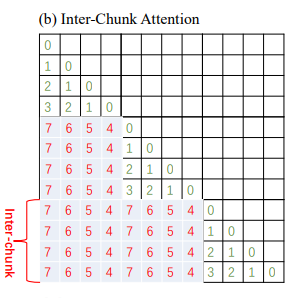
2. Chunk 间注意力(Inter-Chunk Attention)
关注不同 Chunk 之间 token 的关系。为了处理跨 Chunk 的长距离依赖,DCA 并不直接使用巨大的相对位置索引。相反,它将前序 Chunk 中的 token 视为一个整体,或使用特定的位置映射策略,使跨 Chunk 的查询(Query)和键(Key)匹配仍能利用模型学到的位置感知能力。这确保了模型在理解全局上下文时不会迷失。
这种双重方法使模型既能保持对局部细节的连贯理解(Chunk 内),又能把握全局的长程依赖(Chunk 间)。
3. 过渡Chunk注意力(Successive-Chunk Attention)
直接从IntraChunk跳到InterChunk会导致位置编码变化比较剧烈,这样会出现上下文割裂的情况(如上图的0变化到4)。所以提出了Successive-Chunk Attention,来解决过渡的问题。
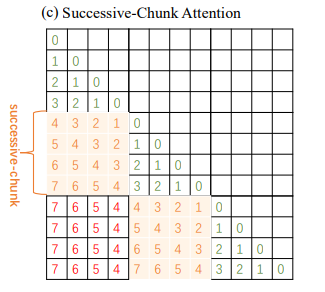
上面三种注意力,用不同位置编码的Q乘以K之后,再将注意力得分进行softmax归一化,最终得到注意力得分矩阵。这种分块算法实现非常契合当flashAttentionV2的算法(分块并行计算),所以在算子和算法实现上能带来较大的便利。
实践
伪代码如下:
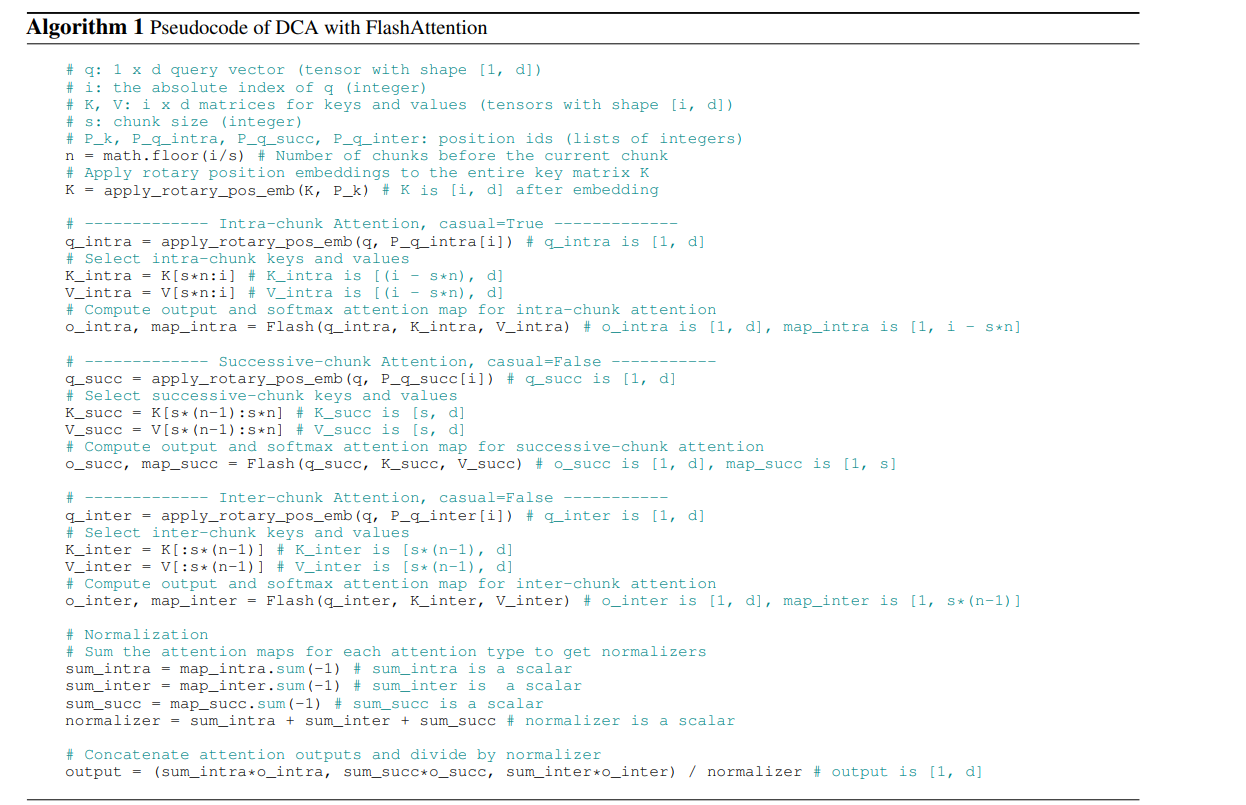
由上述伪代码看出算法大概逻辑是,用三种不同的Q位置编码来计算FlashAttention,算完之后进行归一化处理。
vllm社区已经集成了DCA算法,大致看代码逻辑如下:
特性与性能
- 无需训练:DCA 允许现有模型(如 Llama2 70B)直接扩展上下文窗口,无需额外的梯度更新或参数调整,极大降低了长文本模型的部署门槛。
- 兼容性强:该方法兼容现有注意机制,可无缝集成 Flash Attention,确保推理过程高效且显存占用低,算子融合改造成本低
- 性能卓越:
- 在主要长文本基准测试中,DCA 展现出强大的外推能力。
- 在实际长文本任务中的表现可与专门经过长文本微调的模型相媲美,甚至更优。
- 例如,无需训练的 Llama2-70B 模型在大海捞针等任务中,达到了 GPT-3.5-16k 约 94% 的性能水平,是极具潜力的开源长文本替代方案。
- 效果测评:
其他
虽然通过DCA长度外推后困惑度和大海捞针上表现出色,但是也是避免不了长上下文的腐败问题,大海捞针更加强调的检索能力的验证,实测在总结类的任务上其实表现不了多惊艳,如何在当前的RAG or Agent系统中利用好该算法赋能后的模型检索能力可能是下一步该思考的问题。