KVCache reuse 01
Introduction to no-prefix KVCache reuse

KV Cache 非前缀复用技术对比分析报告
简要总结
本报告深入分析了5篇关于KV Cache非前缀复用的前沿研究论文,包括CacheBlend(芝加哥大学,EuroSys’25)、Cache-Craft(Adobe Research,2025)、EPIC(北京大学/华为云,ICML’25)、REFRAG(Meta,2025)和KVLink(UC Santa Barbara/Accenture,NeurIPS’25)。 今天首先介绍 CacheBlend 与 Cache-Craft。
这些研究共同解决了RAG系统中非前缀位置的文本块KV Cache复用这一核心挑战——传统前缀缓存只能复用输入开头的文本块,而RAG场景下多个检索文档往往以任意顺序拼接在查询之后。 而这种任意顺序的拼接造成 KVCache 不满足前缀复用(prefix-cache)的要求,市面上大部分场景下是进行 KVCache 重新计算,即重新做 Prefill,这会消耗大量计算资源,增加系统的延迟。 如果简单地将不同 KVCache Chunk 直接复用,会导致两个主要问题:
- 位置信息错乱。
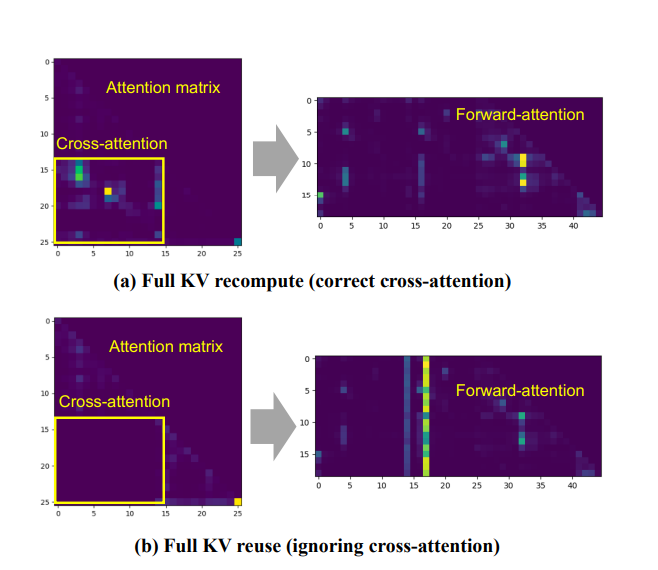
- 跨 Chunk 之间文档的注意力缺失。
为解决上述问题,各论文采用了不同的技术路线:CacheBlend和Cache-Craft通过选择性重计算部分token的KV值来恢复跨块注意力;EPIC提出了LegoLink算法重计算每个块的前k个token;KVLink引入可训练的link token来重建块间连接;REFRAG则采用编码器-解码器架构将文档压缩为chunk embedding。在性能方面,TTFT加速比从2.2×到96%不等,其中KVLink的TTFT降低最显著(最高96%),REFRAG的压缩率最高(16-32×),而CacheBlend和EPIC在保持生成质量的同时实现了2-8×的吞吐量提升。选择建议取决于具体场景:追求极致速度和精度选KVLink,需要系统级优化和存储管理选CacheBlend或Cache-Craft,超长上下文场景选REFRAG,而EPIC提供了精度与速度的最佳平衡。
1. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
1.1 论文基本信息
| 属性 | 内容 |
|---|---|
| 作者 | Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, Junchen Jiang |
| 机构 | University of Chicago, CUHK Shenzhen, Stanford University, Microsoft Research |
| 发表时间 | 2024年5月提交,2025年4月修订,发表于EuroSys 2025 |
| 论文链接 | arXiv:2405.16444 |
| 代码仓库 | LMCache |
1.2 核心问题与动机
在RAG(检索增强生成)系统中,用户查询通常需要配合多个检索到的文本块才能生成准确答案。传统的前缀缓存(Prefix Caching)只能复用输入序列前缀位置的KV Cache,而在RAG场景下,只有第一个检索文档位于前缀位置,后续文档的KV Cache无法被复用。这导致大量冗余计算。
更关键的是,跨块注意力(Cross-Attention) 对于生成质量至关重要。如下图所示,当询问”梅西和罗纳尔多谁在世界杯进球更多”时,需要同时查看两个文本块的信息才能正确回答。如果直接复用各块独立计算的KV Cache(忽略跨块注意力),会导致错误答案。 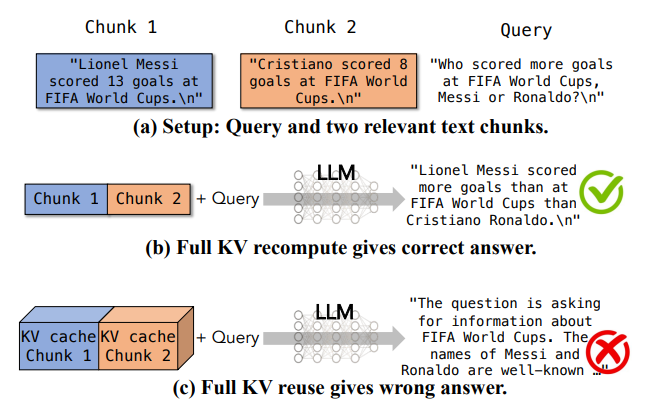
1.3 算法细节
1.3.1 核心思想:选择性KV重计算
CacheBlend的核心创新是选择性重计算(Selective Recomputation)——在复用预计算KV Cache的同时,只重计算一小部分关键token的KV值,以恢复跨块注意力信息。
1.3.2 关键概念定义
| 概念 | 定义 |
|---|---|
| KV Deviation | 复用KV与完整重计算KV之间的绝对差异,衡量token受跨块影响的程度 |
| Attention Deviation | 前向注意力矩阵的L2范数差异,衡量生成质量偏差 |
| HKVD Tokens | High-KV-Deviation Tokens,即KV偏差最高的token |
关键洞察(Insight 1):重计算KV偏差高的token能最大程度降低注意力偏差。
关键洞察(Insight 2):相邻层的HKVD token具有高度相关性(Spearman秩相关系数>0.8),因此可以基于前一层的计算结果预测下一层的重计算目标。
1.3.3 三层级Token选择策略
CacheBlend采用 逐层筛选(Gradual Filtering) 策略选择需要重计算的token:
- 第一层:基于第一层的注意力偏差,选择 $r_1\%$ 的token($r_1$ 略高于目标比例 $r$)
- 中间层:在第 $i$ 层,从上一层筛选出的token中,选择 $r_i\%$ 具有最高KV偏差的token
- 逐层递减:$r_1 > r_2 > … > r_L$,最终每层只重计算约 10-20% 的token
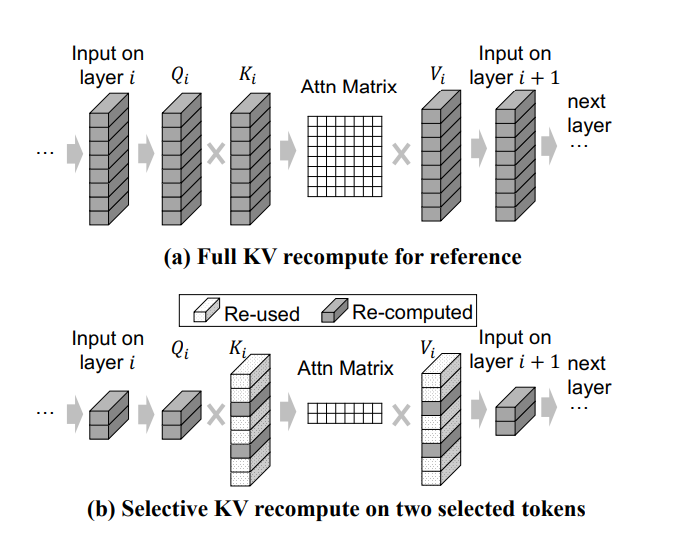
1.3.4 选择性重计算流程
1
2
3
4
5
6
对于每一层 i:
1. 对选中的token应用mask,减少输入规模
2. 计算选中token的Q_i, K_i, V_i
3. 扩展K_i和V_i:复用未选中token的预计算KV Cache
4. 计算注意力矩阵:选中token × 所有token
5. 输出到下一层
1.3.5 系统级优化:流水线设计
CacheBlend的关键系统洞察是:如果选择性重计算的延迟小于KV Cache加载延迟,则可以通过流水线隐藏重计算开销。
- 流水线策略:第 $i$ 层的重计算与第 $i+1$ 层KV Cache的加载并行执行
- 存储层级:预计算KV Cache可以存储在较慢但容量更大的设备(如CPU内存或SSD)
- 零额外延迟:当加载时间 ≥ 重计算时间时,TTFT不会增加
1.4 优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅ 无精度损失:实验表明与完整重计算相比无生成质量下降 | ❌ 实现复杂:需要修改推理引擎的逐层计算流程 |
| ✅ 显著加速:TTFT降低2.2-3.3×,吞吐量提升2.8-5× | ❌ 依赖注意力稀疏性:如果跨块注意力密集,重计算比例需要提高 |
| ✅ 通用性强:适用于任何基于Transformer的LLM | ❌ 内存开销:需要同时存储预计算KV和中间计算结果 |
| ✅ 流水线隐藏延迟:重计算与KV加载并行 | ❌ 离线预处理:需要预先计算并存储所有可能文档的KV |
1.5 适用场景
- 企业级RAG系统:需要处理大量重复文档查询的场景
- 多跳问答(Multi-hop QA):需要联合多个文档信息才能回答的复杂查询
- 长上下文RAG:检索文档数量多、总长度长的场景
- 高质量要求场景:对生成质量要求严格、不能接受精度损失的应用
1.6 实验结果
| 指标 | 结果 |
|---|---|
| TTFT加速 | 2.2-3.3× |
| 吞吐量提升 | 2.8-5× |
| 重计算比例 | 10-20% |
| 精度保持 | 与完整重计算无显著差异 |
| 测试模型 | Mistral-7B, Yi-34B, Llama-70B |
| 测试数据集 | Musique, 2WikiMQA, NaturalQuestions, TriviaQA |
2. Cache-Craft: Managing Chunk-Caches for Efficient Retrieval-Augmented Generation
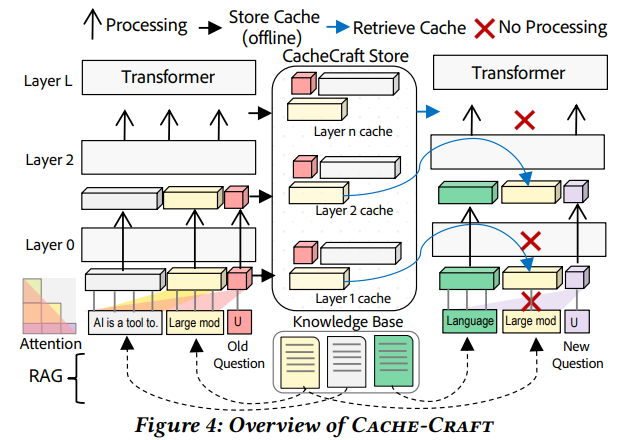
2.1 论文基本信息
| 属性 | 内容 |
|---|---|
| 作者 | Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Mahapatra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, Shiv Saini |
| 机构 | Adobe Research, IIT Bombay, IIT Kanpur |
| 发表时间 | 2025年2月(arXiv:2502.15734) |
| 论文链接 | arXiv:2502.15734 |
2.2 核心问题与动机
Cache-Craft针对RAG系统中的chunk-cache管理问题,提出了三个关键观察:
- 重复检索模式:在生产级RAG系统(Sys-X和Sys-Y)中,75%的检索块会被重复处理,每月产生约120亿token的重复计算
- 块间注意力稀疏性:通过分析发现,大部分token主要受同一块内其他token的影响,只有少数token受到其他块的显著影响
- 前缀顺序敏感性:即使包含相同的检索块,不同的排列顺序也会影响复用效果(Lost-in-the-Middle现象)
2.3 算法细节
KVCache Chunk Varient:同一 KVCache 可能在不同历史请求里出现过,形成多个“带不同前缀语境”的 KVCache 版本, 被称为 KVCache Chunk varient (简称 varient)。 算法的核心在于将多个不同语境的 varient 进行集中管理、淘汰,在遇到需要复用的时候,对不同的 varient 进行在线评分,选取适合的 varient 进行复用。
2.3.1 核心概念:Chunk-Cache
Cache-Craft将每个文本块的预计算KV Cache称为chunk-cache,并定义了三个关键指标来评估其可复用性:
| 指标 | 定义 | 用途 |
|---|---|---|
| Inter-Attention | 块间注意力权重之和 | 衡量块受其他块影响的程度 |
| Intra-Attention | 块内注意力权重之和 | 衡量块的自包含程度 |
| CCI (Cache Context Impact) | $CCI(C_i) = \frac{1}{1 + e^{-\bar{a}/\bar{b}}}$ | 综合评估块的外部依赖程度 |
其中 $\bar{a}$ 是归一化的inter-attention,$\bar{b}$ 是归一化的intra-attention。CCI越接近1,表示块越依赖外部上下文,复用难度越大。
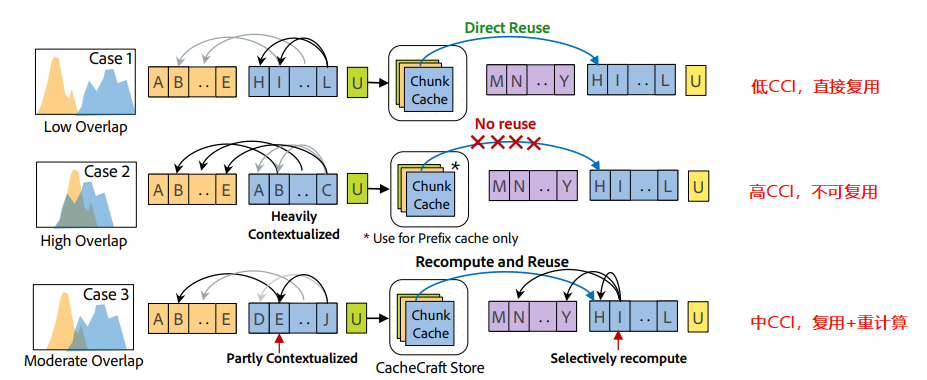
2.3.2 前缀重叠评分(Prefix Overlap Score)
为了评估chunk-cache在新查询中的复用性,Cache-Craft定义了Adjusted Prefix Overlap Score:
\[\beta'(C_i | S_{new}) = \beta(C_i | S_{new}) \cdot (1 - \gamma(C_i | S_{new}))\]其中:
- $\beta$ 是基于inter-attention的简单重叠评分
- $\gamma$ 是Order Penalty Score(基于Kendall’s Tau距离),用于惩罚前缀顺序的差异
2.3.3 自适应重计算策略
Cache-Craft根据CCI评分决定重计算策略:
| CCI范围 | 策略 | 描述 |
|---|---|---|
| 低CCI(<0.3) | 直接复用 | 块自包含性强,直接复用 |
| 中CCI(0.3-0.7) | 选择性重计算 | 重计算top-N个高inter-attention token |
| 高CCI(>0.7) | 完全重计算 | 块高度依赖外部上下文,不复用 |
重计算token选择: \(T(C_i) = \arg\text{top}_N \left\{ \sum_{j<i} \text{inter}(C_j, t_k) \mid t_k \in C_i \right\}\)
| 其中 $N = \lceil CFO(C_i) \cdot | C_i | \rceil$,$CFO$(Cache Fix Overhead)是基于CCI和$\beta’$计算的。 |
2.3.4 自适应早期终止(Adaptive Early Termination)
Cache-Craft利用RAG的标准实践——检索足够多的块然后用LLM过滤无关内容——来减少运行时重计算:
- 监控层间注意力:在每层重计算时,监控块与当前问题的inter-attention
- 识别Focused Chunks:发现约80%的查询在10-15层后,focused chunks(与问题高度相关的块)可以被明确区分
- 早期终止:对”unfocused chunks”提前终止重计算,显著降低计算成本
2.3.5 存储与驱逐策略
Cache-Craft设计了高效的chunk-cache存储系统:
- 元数据存储:每个chunk-cache的CCI、原始上下文、位置信息等
- 分层存储:热数据保留在GPU显存,冷数据迁移到CPU内存或SSD
- 智能驱逐:基于访问频率、CCI评分(低CCI优先保留,因为复用价值高)和缓存大小进行LRU-like驱逐
2.4 CacheChunk 以及主要算法的伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
@dataclass
class ChunkVariant:
"""
Chunk-Cache 的一个变体,记录特定上下文下的缓存状态
"""
variant_id: int
# 该变体对应的上下文(前缀 chunks 的 ID 列表)
context_chunk_ids: List[int]
# CCI 分数: 该 chunk 受外部上下文影响的程度 [0, 1]
cci: float
# 归一化的 inter-attention 分数(来自前缀的影响)
inter_attention: float
# 归一化的 intra-attention 分数(块内自注意力)
intra_attention: float
# 需要重计算的 token 索引列表(按 inter-attention 排序)
recomputed_tokens: List[int]
# 重计算比例 [0, 1]
recompute_ratio: float
# 访问计数(用于 LRU 驱逐策略)
access_count: int = 0
# 最后访问时间戳
last_access_time: float = 0.0
class ChunkCache:
"""
Cache-Craft 核心类:管理单个文本块的多个缓存变体
"""
def __init__(self, chunk_id: int, tokens: List[int], layer_count: int = 32):
"""
初始化 Chunk-Cache
Args:
chunk_id: 该 chunk 的全局唯一 ID
tokens: chunk 的 token ID 列表
layer_count: 模型层数(用于计算注意力统计)
"""
self.chunk_id = chunk_id
self.tokens = tokens # List[int]
self.token_count = len(tokens)
self.layer_count = layer_count
# 变体存储: context_signature -> ChunkVariant
# context_signature 是排序后的 context_chunk_ids 元组
self.variants: Dict[Tuple[int, ...], ChunkVariant] = {}
# 该 chunk 的全局统计(跨所有层平均)
self.global_inter_attention = 0.0
self.global_intra_attention = 0.0
# 每层每个 token 的 inter-attention 分数(用于选择重计算 token)
# shape: [layer_count, token_count]
self.token_inter_attention_per_layer: List[List[float]] = []
# 元数据
self.creation_time = 0.0
self.total_access_count = 0
# ==================== 核心算法方法 ====================
def compute_cci(self, inter_attn: float, intra_attn: float) -> float:
"""
计算 Cache Context Impact (CCI)
CCI = 1 / (1 + e^(-a/b))
其中 a = inter_attention, b = intra_attention
CCI 接近 1: chunk 高度依赖外部上下文,复用困难
CCI 接近 0: chunk 自包含,易于复用
"""
pass
def compute_prefix_overlap_score(
self,
old_context: List[int],
new_context: List[int],
inter_attention_matrix: Dict[Tuple[int, int], float]
) -> float:
"""
计算前缀重叠评分 β
β(Ci | S_new) = Σ inter(i,j) for j in (S_old ∩ S_new) / Σ inter(i,j) for j in S_old
Args:
old_context: 原始上下文 chunk IDs
new_context: 新查询的上下文 chunk IDs
inter_attention_matrix: 当前 chunk 与各前缀 chunk 的 inter-attention 分数
Returns:
β 分数 [0, 1]
"""
pass
def compute_cache_fix_overhead(
self,
cci: float,
adjusted_beta: float
) -> float:
"""
计算 Cache Fix Overhead (CFO)
CFO 决定了需要重计算的 token 比例
论文中通过离线分析建立 CCI、1-β' 与输出偏差的关系
这里简化为线性组合
"""
pass
def select_tokens_for_recomputation(
self,
cfo: float,
layer: int = 0
) -> List[int]:
"""
选择需要重计算的 token
策略: 选择 inter-attention 分数最高的 top-N 个 token
N = ceil(CFO * |Ci|)
Args:
cfo: Cache Fix Overhead
layer: 当前层(默认使用第 0 层统计)
Returns:
需要重计算的 token 索引列表
"""
pass
# ==================== 变体管理方法 ====================
def add_variant(
self,
context_chunk_ids: List[int],
inter_attention: float,
intra_attention: float,
inter_attention_matrix: Dict[Tuple[int, int], float],
timestamp: float = 0.0
) -> ChunkVariant:
"""
添加一个新的 chunk-cache 变体
Args:
context_chunk_ids: 该变体对应的上下文 chunk IDs
inter_attention: 归一化的 inter-attention 分数
intra_attention: 归一化的 intra-attention 分数
inter_attention_matrix: 完整的 inter-attention 矩阵
timestamp: 创建时间戳
Returns:
新创建的 ChunkVariant
"""
pass
def get_best_variant(
self,
target_context: List[int],
inter_attention_matrix: Dict[Tuple[int, int], float],
threshold_cci: float = 0.7,
threshold_beta: float = 0.5
) -> Optional[Tuple[ChunkVariant, float, str]]:
"""
获取最适合目标上下文的最佳变体
策略:
1. 计算每个变体的 Adjusted Prefix Overlap Score
2. 筛选 CCI < threshold_cci 且 β' > threshold_beta 的变体
3. 选择 β' 最高的变体
Args:
target_context: 目标上下文 chunk IDs
inter_attention_matrix: inter-attention 矩阵
threshold_cci: CCI 阈值(高于此值认为不可复用)
threshold_beta: β' 阈值(低于此值认为复用价值低)
Returns:
(最佳变体, β' 分数, 复用策略) 或 None(无可复用变体)
复用策略: "direct" | "selective_recompute" | "no_reuse"
"""
pass
2.5 优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅ 精细的复用决策:CCI和Prefix Overlap Score提供了量化的复用评估 | ❌ 预处理开销:需要为每个chunk计算inter/intra-attention |
| ✅ 自适应重计算:根据块的依赖程度动态调整重计算比例 | ❌ 元数据存储成本:需要存储额外的注意力统计信息 |
| ✅ 早期终止优化:利用RAG特性减少不必要的计算 | ❌ 参数调优:CCI阈值、重计算比例等参数需要针对具体模型调优 |
| ✅ 生产级设计:考虑了真实RAG系统的存储、驱逐等实际问题 | ❌ 顺序敏感性:Kendall’s Tau距离计算增加了复杂度 |
2.6 适用场景
- 大规模生产RAG系统:需要处理高并发、大量重复文档的场景
- 动态知识库:文档频繁更新、需要智能缓存管理的场景
- 资源受限环境:需要在GPU显存、CPU内存、SSD之间平衡存储的场景
- 多租户RAG服务:不同用户查询模式不同,需要自适应复用策略
2.7 实验结果
| 指标 | 结果 |
|---|---|
| 冗余计算减少 | 比前缀缓存减少51%,比完整重计算减少75% |
| 吞吐量提升 | 1.6×(连续批处理场景) |
| 端到端延迟降低 | 2× |
| 测试模型 | LLaMA-3-8B, LLaMA-3-70B |
| 测试场景 | 两个真实生产RAG系统(Sys-X和Sys-Y) |